Explicación del procesamiento de datos: De los datos brutos a la información LiDAR

Dar sentido a los datos en un mundo basado en ellos
De la sobrecarga de datos en bruto…
Estamos rodeados de datos en bruto: desde clics de clientes en Internet hasta paisajes en 3D capturados por dispositivos de escaneado láser como LiDAR. Cada día, enormes volúmenes de información fluyen desde sensores, ventas online, encuestas a clientes o los sistemas LiDAR que ofrece YellowScan.
Pero los datos en bruto no equivalen automáticamente a información útil:hay que procesarlos con precisión. Aunque la abundancia de datos pueda parecer beneficiosa, una gran parte permanece sin utilizar, desorganizada o infrautilizada, dispersa por los sistemas de almacenamiento y ofreciendo poco o ningún valor tangible. Para liberar su potencial, los datos deben ser estructurados, refinados y dotados de significado.
…a información empresarial útil
El valor real sólo surge cuando procesamos eficazmente esta entrada bruta mediante operaciones de datos estructurados. ¿Cómo transformamos números, texto y puntos en decisiones empresariales más inteligentes? La clave está en el procesamiento de datos. Piensa en él como el puente esencial desde la entrada desordenada a la información clara y procesable, que permite mejores análisis y decisiones informadas. Ya sea para mejorar las operaciones empresariales, explorar nuevas fronteras tecnológicas o utilizar herramientas avanzadas como LiDAR, que requiere pasos específicos de procesamiento de datos, comprender el tratamiento eficaz de los datos es crucial para las empresas hoy en día. Vamos a esbozar las principales etapas del procesamiento de datos.

El sistema LiDAR YellowScan Mapper+ escanea el paisaje para la vigilancia medioambiental
¿Qué es el tratamiento de datos?
Definición del núcleo y operaciones
En esencia, el procesamiento de datos significa realizar operaciones sistemáticas con los datos brutos para convertirlos en información significativa y estructurada. Estas tareas suelen incluir la clasificación, limpieza (preparación de datos), conversión de formatos, análisis y almacenamiento seguro de datos. Los sistemas modernos dependen en gran medida del software especializado y la automatización(procesamiento automático de datos) para ser eficientes, garantizando una mayor calidad y coherencia de los datos en grandes conjuntos de datos.
Objetivos y enfoques principales
¿El objetivo principal? Transformar una entrada desorganizada en una salida organizada y clara, lista para la toma de decisiones o el análisis posterior. Una buena gestión de la información hace que los datos sean comprensibles y fiables para la empresa, apoyando desde las operaciones diarias hasta la estrategia a largo plazo. En resumen, una gestión eficaz de los datos convierte el ruido en significado. Esto puede abarcar desde el trabajo manual, propenso a errores y escalas de tiempo más lentas, hasta sistemas totalmente automatizados que aprovechan algoritmos, ciencia de datos y aprendizaje automático. Sin embargo, los controles humanos siguen siendo importantes para la confianza, el contexto y las consideraciones éticas, especialmente cuando se trata de datos personales.
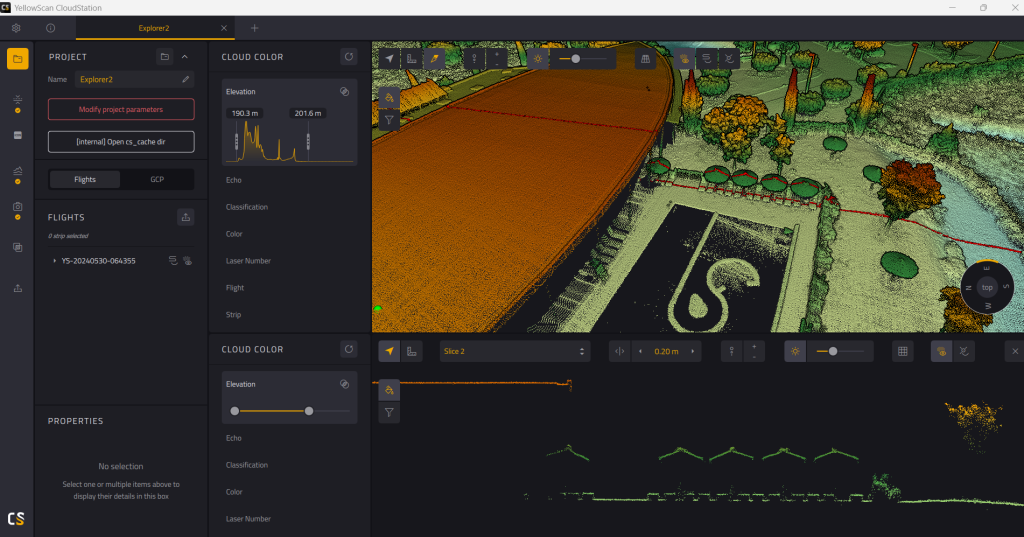
El software YellowScan CloudStation garantiza una alta calidad de los datos
Las 6 etapas fundamentales del ciclo de tratamiento de datos
Las operaciones de datos eficaces suelen seguir este ciclo de procesamiento de datos. Cada paso es crucial para el éxito global.
1. Recogida de datos
Esta fase inicial implica recopilar sistemáticamente datos sin procesar de fuentes de datos relevantes: sensores, formularios, interacciones con clientes, sistemas empresariales, registros electrónicos, dispositivos de recopilación especializados o equipos como escáneres LiDAR. La calidad de la entrada afecta a todos los resultados; una recopilación exhaustiva y precisa es primordial para un análisis significativo.
2. Preparación de datos (limpieza)
La preparación de los datos, que suele ser la fase que más tiempo consume, consiste en ordenar los datos brutos: corregir errores, eliminar duplicados, tratar los valores que faltan y crear un formato coherente para su posterior procesamiento y análisis. Garantizar aquí una alta calidad de los datos evita costosos errores posteriores. Este paso es vital (“basura dentro, basura fuera”) para obtener información fiable.
3. Entrada de datos
Introduce los datos limpios en el sistema de procesamiento de datos de destino (software específico, base de datos como MySQL o servicios de almacenamiento en la nube). Los datos deben estar en un formato que el sistema pueda leer y comprender, lo que puede implicar su transformación o codificación.
4. Procesamiento activo de datos
Los algoritmos o la IA procesan los datos basándose en reglas u objetivos, realizando cálculos, ordenando, clasificando o encontrando patrones para extraer información valiosa. A menudo se necesitan potentes recursos informáticos. La automatización desempeña un papel muy importante, ya que utiliza métodos definidos y herramientas especializadas para realizar tareas complejas mucho más rápidamente que el análisis manual.
5. Salida de datos
Presenta la información procesada de forma útil mediante informes, cuadros de mando para análisis, archivos estructurados o alertas. Los resultados deben ser claros y fácilmente interpretables por los usuarios u otros sistemas para una toma de decisiones eficaz. Las visualizaciones suelen ayudar a comunicar los resultados.
6. Almacenamiento de datos
Archiva de forma segura los resultados procesados y, a veces, los datos sin procesar para su uso futuro, auditorías de cumplimiento o análisis posteriores. Unas estrategias de almacenamiento de datos adecuadas garantizan la disponibilidad y una sólida protección de los datos. Las soluciones de almacenamiento optimizadas (en las instalaciones o en la nube) son cruciales para gestionar los costes y la seguridad.
Estos seis pasos son fundamentales para manejar conjuntos de datos sencillos o complejos análisis de big data, incluidos los exigentes proyectos de escaneado 3D.
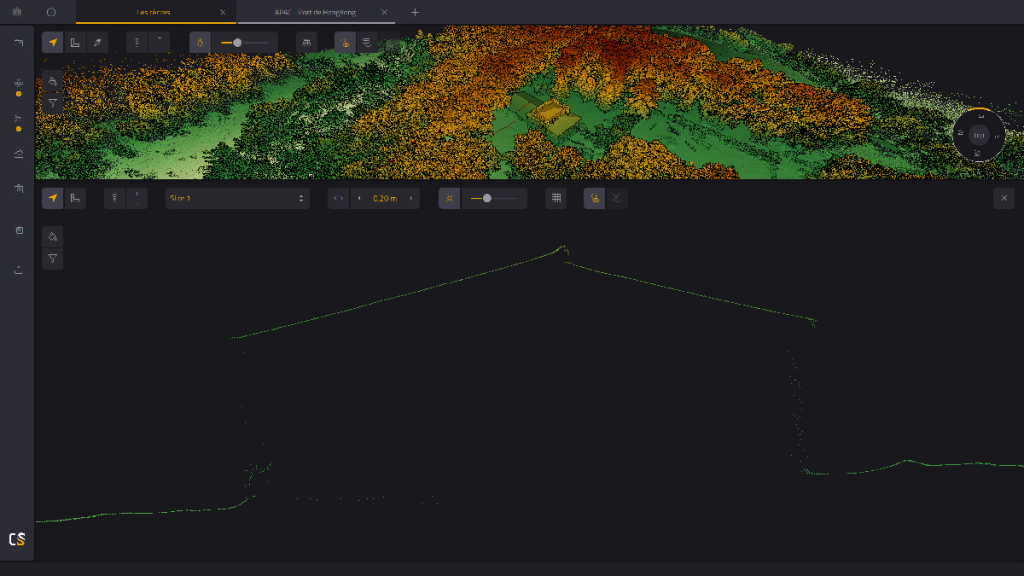
Nube de puntos limpia visualizada en YellowScan CloudStation
Explorar distintos tipos de tratamiento de datos
Los distintos métodos de procesamiento de datos se adaptan a necesidades diferentes, dependiendo de factores como el volumen, la velocidad y la conectividad. Comprender estos tipos ayuda a las empresas a elegir sabiamente.
Procesamiento por lotes
Recoge datos a lo largo del tiempo y los procesa en grandes lotes; adecuado para tareas no urgentes y de gran volumen, como la facturación o los grandes informes.
Procesamiento en tiempo real
Maneja datos casi instantáneamente, esencial para reacciones inmediatas como la detección de fraudes o la navegación autónoma utilizando datos en tiempo real. Requiere sistemas con capacidad de respuesta.
Procesamiento de transacciones en línea (OLTP)
Gestiona muchas transacciones de clientes rápidas y simultáneas (por ejemplo, pedidos en línea), centrándose en la velocidad y la precisión dentro del sistema operativo.
Procesamiento distribuido
Divide las cargas de trabajo de big data en varios ordenadores (a menudo basados en la nube) para obtener velocidad y potencia en análisis complejos, permitiendo la ciencia de datos a gran escala.
Procesamiento de bordes
Realiza las operaciones iniciales de los datos en el dispositivo de recogida o cerca de él (por ejemplo, sensores IoT, drones), útil en caso de baja latencia o conectividad deficiente, preprocesando la información (procesando los datos cerca de la fuente (por ejemplo, sensores) para una baja latencia).
La elección del enfoque adecuado implicará a menudo estrategias híbridas. Por ejemplo, cómputos de borde para alertas inmediatas combinados con procesamiento central por lotes para análisis históricos profundos, lo que permite a las empresas adaptar sus operaciones.
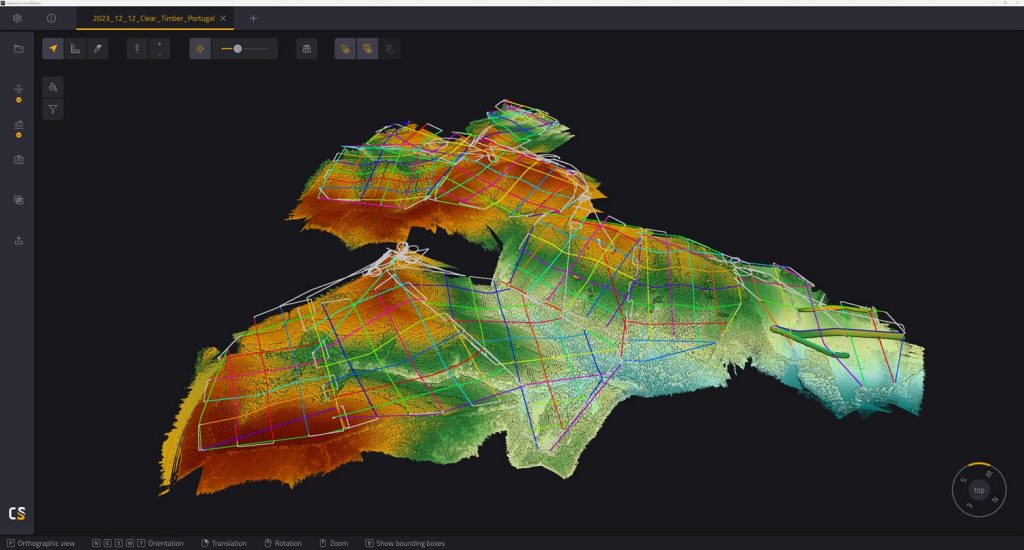
Datos de nubes de puntos de gran volumen procedentes de múltiples vuelos procesados en el software YellowScan CloudStation
Ventajas estratégicas de un tratamiento de datos eficaz
Implantar una gestión eficaz de la información aporta importantes ventajas empresariales:
- Mayor precisión: Unas salidas limpias y bien procesadas conducen a resultados fiables.
- Información más rápida: La automatización acelera la obtención de información procesable a partir de los análisis.
- Escalabilidad: Los buenos sistemas manejan volúmenes de datos crecientes, algo vital para los big data.
- Rentabilidad: La automatización de tareas reduce el esfuerzo manual y los gastos operativos.
- Cumplimiento: Las operaciones estructuradas ayudan a cumplir las leyes de protección de datos, como la GDPR.
- Mejor colaboración: Los datos normalizados facilitan el intercambio de información.
- Ventaja competitiva: Unos análisis mejores y más rápidos informan de movimientos empresariales más inteligentes.
- Mejora de las previsiones: El análisis de datos históricos ayuda a realizar predicciones más precisas.
El tratamiento eficaz de los datos desbloquea su valor, convirtiéndolos en inteligencia empresarial e información crucial sobre los clientes.
Superar los retos habituales del tratamiento de datos
Un tratamiento eficaz de los datos exige anticiparse a los obstáculos.
Garantizar la calidad de los datos en el tratamiento de datos
Los retos suelen estar relacionados con la calidad de los datos. Los formatos incoherentes de fuentes variadas requieren una normalización mediante herramientas de preparación. Los datos que faltan o son malos pueden corromper el análisis; las soluciones implican comprobaciones de errores y estrategias claras para las lagunas.
Gestión de recursos y seguridad
La gestión de recursos y la seguridad plantean obstáculos. Los grandes volúmenes y costes de los big data (como los grandes archivos de escaneado láser) exigen recursos y almacenamiento potentes. Las estrategias de almacenamiento eficientes, los procedimientos optimizados o los servicios de computación en nube (como AWS, Microsoft Azure, Google Cloud) ayudan. Una seguridad y privacidad sólidas son fundamentales para los datos personales, ya que requieren encriptación, controles de acceso y cumplimiento de las normas y la ley de protección de datos (por ejemplo, el GDPR). Todo responsable del tratamiento de datos tiene responsabilidades en virtud de la ley.
Abordar la complejidad de las herramientas
Por último, las herramientas pueden ser un obstáculo. Algunos programas informáticos de procesamiento presentan a las Herramientas Complejas una curva de aprendizaje pronunciada, que requiere conocimientos especializados o un extenso trabajo manual. La mitigación pasa por la formación y la selección de sistemas fáciles de usar. Conviene leer los términos técnicos de los programas o servicios específicos.
Planificar de forma proactiva estos retos hace que el flujo de trabajo sea más fluido.
El tratamiento de datos en acción: Ejemplos concretos
El impacto de las operaciones de datos abarca muchas industrias, mostrando cómo el procesamiento aporta valor.
Aplicaciones Geoespaciales, Medioambientales y Urbanas
Cartografía Geoespacial y LiDAR utiliza el procesamiento para obtener mapas 3D precisos, clasificación de la vegetación, BIM o inspección de infraestructuras mediante escaneado láser. El Medio Ambiente y la Agricultura lo aplican para controlar el uso del suelo y orientar la agricultura de precisión. La Planificación Urbana utiliza el análisis de datos de sensores para mejorar la vida en la ciudad. La Gestión de Riesgos, por ejemplo, aprovecha el análisis de datos en tiempo real para predecir catástrofes.
Operaciones empresariales e infraestructura
Las plataformas de comercio electrónico analizan los datos de los clientes para hacer recomendaciones y gestionar las existencias mediante potentes análisis. El transporte y la movilidad dependen del procesamiento de datos de sensores en tiempo real (GPS, escaneado 3D) para la navegación autónoma. El sector de la Energía y los Servicios Públicos utiliza datos procesados para la gestión de la red y el mantenimiento predictivo. Muchas empresas utilizan estos conocimientos.
Avances sanitarios
La sanidad se beneficia enormemente: el procesamiento de imágenes médicas ayuda al diagnóstico, el análisis de sensores portátiles ayuda a controlar la salud, y el análisis de los historiales de los pacientes (garantizando la protección de los datos) mejora los tratamientos. La ciencia de datos aplicada a los datos procesados ayuda a descubrir patrones.
De hecho, la gestión eficaz de la información es clave para convertir los datos brutos en conocimientos procesables.

Clasificación de la vegetación en YellowScan CloudStation

Nube de puntos de una red viaria periférica utilizada para la planificación urbana
Elegir las herramientas adecuadas
Tanto si se trata de terabytes de datos de escaneado láser como de transacciones de clientes, un procesamiento de datos eficiente proporciona una ventaja competitiva. Los retos persisten. Elegir las herramientas y el sistema de software adecuados es crucial. La plataforma adecuada agiliza los flujos de trabajo, garantiza la calidad de los datos, gestiona el volumen y proporciona análisis fiables. El procesamiento inteligente es estratégico, ya que reduce la dependencia de la lenta clasificación manual. Las buenas herramientas de software acortan la distancia entre el potencial bruto y los resultados valiosos.

Sistemas YellowScan LiDAR
Optimiza tu flujo de trabajo LiDAR con CloudStation
Para los profesionales de LiDAR, manejar datos de nubes de puntos es clave. Plataformas como YellowScan CloudStation lo simplifican. Esta herramienta de software segura automatiza los pasos de procesamiento complejos, garantiza resultados coherentes y ayuda a los equipos a colaborar compartiendo los datos procesados y las perspectivas. Sus capacidades de análisis especializado ayudan a convertir más rápidamente los datos LiDAR sin procesar en información valiosa. Más información sobre cómo CloudStation simplifica tu flujo de trabajo de procesamiento LiDAR.
Preguntas frecuentes
¿Qué es el procesamiento de datos LiDAR?
Convertir nubes de puntos LiDAR 3D sin procesar en información útil, como mapas, modelos o mediciones, utilizando métodos y herramientas específicos.
¿Qué se necesita para procesar datos LiDAR?
Sensores precisos, buenos datos GPS/IMU, software especializado y suficiente potencia informática (CPU, RAM, almacenamiento).
¿Cómo se recogen los datos LiDAR?
Utilizando sistemas LiDAR en plataformas que envían impulsos láser y miden el tiempo de retorno. Suelen incluir componentes electrónicos avanzados.
¿Qué es el LiDAR en la anotación de datos?
Etiquetar objetos en nubes de puntos 3D, a menudo utilizando modelos de ciencia de datos y aprendizaje automático entrenados en datos de escaneado láser.
¿Por qué utilizar datos LiDAR?
Proporciona información espacial 3D precisa y de alta resolución a partir del escaneado 3D.
¿Cómo se recogen los datos LiDAR?
Con una plataforma que lleve un sistema de escaneado láser y electrónica de navegación para capturar datos de nubes de puntos. También es importante un almacenamiento eficiente en el dispositivo de recogida.