Le traitement des données expliqué : Des données brutes aux informations LiDAR

Donner du sens aux données dans un monde dominé par les données
De la surcharge de données brutes…
Nous sommes entourés de données brutes, qu’il s’agisse de clics de clients en ligne ou de paysages en 3D capturés par des dispositifs de balayage laser tels que LiDAR. Chaque jour, de vastes volumes d’informations proviennent de capteurs, de ventes en ligne, d’enquêtes auprès des clients ou des systèmes LiDAR proposés par YellowScan.
Mais les données brutes ne sont pas automatiquement synonymes d’informations utiles – ellesdoivent être traitées avec précision. Si l’abondance de données peut sembler bénéfique, une grande partie reste inutilisée, désorganisée ou sous-utilisée, dispersée dans les systèmes de stockage et n’offrant que peu ou pas de valeur tangible. Pour libérer leur potentiel, les données doivent être structurées, affinées et rendues significatives.
…vers des informations commerciales exploitables
La valeur réelle n’apparaît que lorsque nous traitons efficacement ces données brutes par le biais d’opérations de données structurées. Comment transformer les chiffres, le texte et les points en décisions commerciales plus intelligentes ? La clé réside dans le traitement des données. Considérez-le comme la passerelle essentielle entre des données désordonnées et des informations claires et exploitables, permettant de meilleures analyses et des choix éclairés. Qu’il s’agisse d’améliorer les opérations commerciales, d’explorer de nouvelles frontières technologiques ou d’utiliser des outils avancés tels que le LiDAR, qui nécessite des étapes spécifiques de traitement des données, il est essentiel pour les entreprises d’aujourd’hui de comprendre le traitement efficace des données. Décrivons les principales étapes du traitement des données.

Le système LiDAR YellowScan Mapper+ scanne le paysage pour la surveillance de l’environnement
Qu’est-ce que le traitement des données ?
Définition et fonctionnement de base
Le traitement des données consiste essentiellement à effectuer des opérations systématiques sur des données brutes afin de les convertir en informations significatives et structurées. Ces tâches comprennent généralement le tri, le nettoyage (préparation des données), la conversion de format, l « analyse et le stockage sécurisé des données. Les systèmes modernes s’appuient largement sur des logiciels spécialisés et sur l »automatisation(traitement automatique des données) pour plus d’efficacité, ce qui garantit une meilleure qualité des données et une plus grande cohérence entre les grands ensembles de données.
Principaux objectifs et approches
L’objectif principal ? Transformer des données d’entrée désorganisées en données de sortie organisées et claires, prêtes à être utilisées pour la prise de décision ou pour d’autres analyses. Une bonne gestion de l’information rend les données compréhensibles et fiables pour l’entreprise, soutenant tout, des opérations quotidiennes à la stratégie à long terme. En bref, une gestion efficace des données transforme le bruit en signification. Cela peut aller du travail manuel, sujet à des erreurs et à des échelles de temps plus lentes, à des systèmes entièrement automatisés utilisant des algorithmes, la science des données et l’apprentissage automatique. Toutefois, les contrôles humains restent importants pour la confiance, le contexte et les considérations éthiques, en particulier lorsqu’il s’agit de données personnelles.
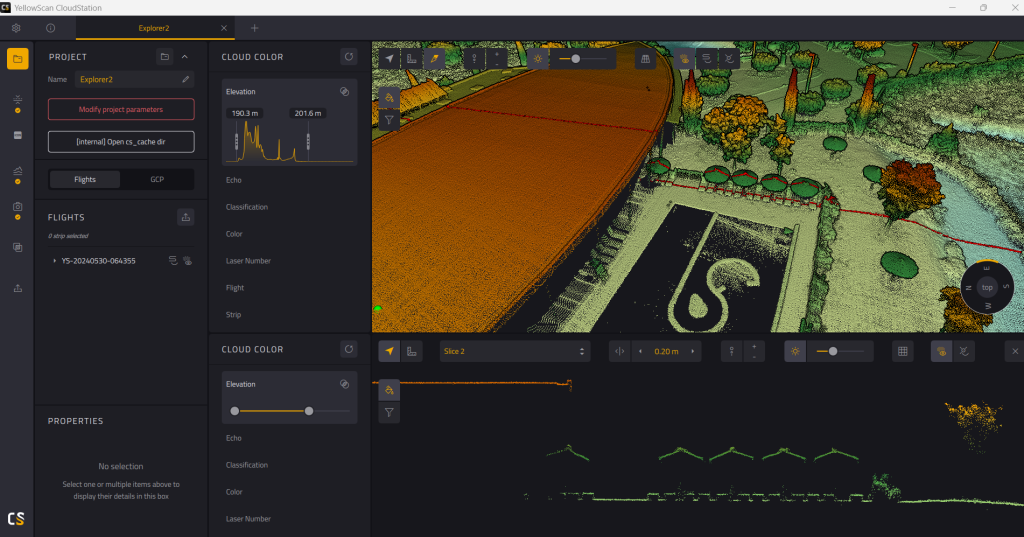
Le logiciel YellowScan CloudStation garantit une qualité élevée des données
Les 6 étapes fondamentales du cycle de traitement des données
Les opérations de données efficaces suivent généralement ce cycle de traitement des données. Chaque étape est cruciale pour la réussite globale.
1. Collecte des données
Cette première étape consiste à collecter systématiquement des données brutes à partir de sources de données pertinentes – capteurs, formulaires, interactions avec les clients, systèmes d’entreprise, enregistrements électroniques, dispositifs de collecte spécialisés ou équipements tels que les scanners LiDAR. La qualité des données d’entrée a une incidence sur tous les résultats ; une collecte complète et précise est essentielle pour obtenir des analyses significatives.
2. Préparation des données (nettoyage)
Souvent la phase la plus longue, la préparation des données consiste à mettre de l’ordre dans les données brutes : corriger les erreurs, supprimer les doublons, traiter les valeurs manquantes et créer un format cohérent pour le traitement et l « analyse ultérieurs. Garantir la qualité des données à ce stade permet d » éviter des erreurs coûteuses en aval. Cette étape est vitale (« garbage in, garbage out ») pour obtenir des informations fiables.
3. Entrée des données
Introduisez les données propres dans le système de traitement des données cible (logiciel spécifique, base de données comme MySQL ou services de stockage en nuage). Les données doivent être dans un format que le système peut lire et comprendre, ce qui peut impliquer une transformation ou un encodage.
4. Traitement actif des données
Les algorithmes ou l’IA traitent les données sur la base de règles ou d’objectifs, en effectuant des calculs, en triant, en classant ou en trouvant des modèles afin d’extraire des informations utiles. De puissantes ressources informatiques sont souvent nécessaires. L’automatisation joue un rôle important, en utilisant des méthodes définies et des outils spécialisés pour traiter des tâches complexes beaucoup plus rapidement que l’analyse manuelle.
5. Sortie des données
Présenter les informations traitées de manière utile au moyen de rapports, de tableaux de bord pour l’analyse, de fichiers structurés ou d’alertes. Les résultats doivent être clairs et facilement interprétables par les utilisateurs ou d’autres systèmes pour une prise de décision efficace. Les visualisations aident souvent à communiquer les résultats.
6. Stockage des données
Archivez en toute sécurité les résultats traités et parfois les données brutes en vue d’une utilisation ultérieure, d’un audit de conformité ou d’une analyse plus poussée. Des stratégies de stockage des données appropriées garantissent la disponibilité et une protection solide des données. Des solutions de stockage optimisées (sur site ou dans le nuage) sont essentielles pour gérer les coûts et la sécurité.
Ces six étapes sont fondamentales pour traiter des ensembles de données simples ou des analyses complexes de big data, y compris des projets de numérisation 3D exigeants.
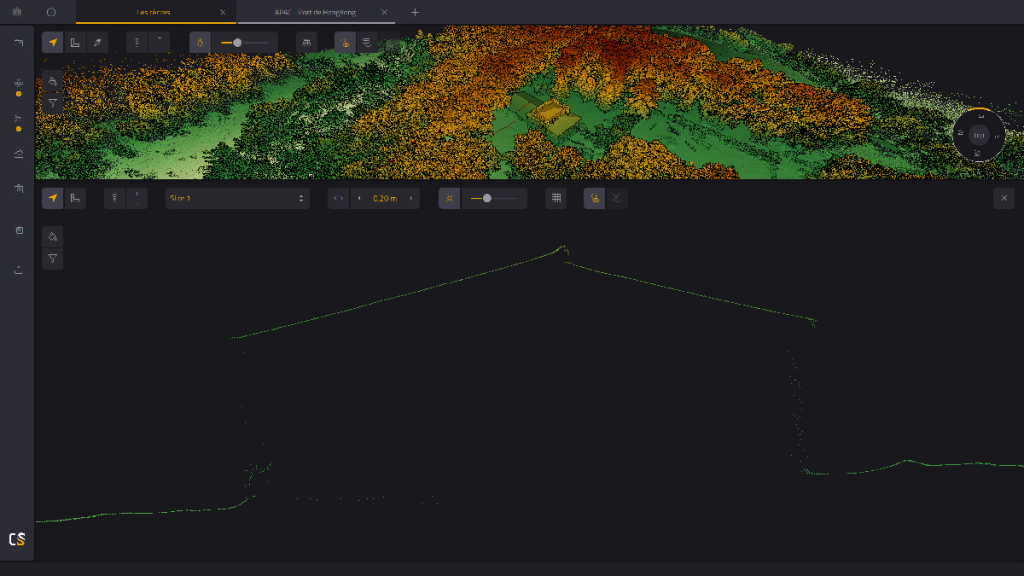
Tranche de nuage de points propre visualisée dans YellowScan CloudStation
Explorer les différents types de traitement des données
Diverses méthodes de traitement des données répondent à des besoins différents, en fonction de facteurs tels que le volume, la vitesse et la connectivité. Comprendre ces types de méthodes permet aux entreprises de faire un choix judicieux.
Traitement par lots
Collecte des données au fil du temps et les traite par lots importants ; convient aux tâches non urgentes et à fort volume, telles que la facturation ou les rapports volumineux.
Traitement en temps réel
Traite les données presque instantanément, ce qui est essentiel pour des réactions immédiates telles que la détection des fraudes ou la navigation autonome à l’aide de données en temps réel. Nécessite des systèmes réactifs.
Traitement des transactions en ligne (OLTP)
Gérer de nombreuses transactions rapides et simultanées avec les clients (par exemple, des commandes en ligne), en mettant l’accent sur la rapidité et la précision au sein du système opérationnel.
Traitement distribué
Répartit les charges de travail des big data sur plusieurs ordinateurs (souvent basés sur le cloud) pour accélérer les analyses complexes et les rendre plus puissantes, ce qui permet de faire de la science des données à grande échelle.
Traitement des bords
Effectue des opérations initiales sur les données sur ou à proximité du dispositif de collecte (par exemple, capteurs IoT, drones), utiles en cas de faible latence ou de mauvaise connectivité en prétraitement des informations (traitement des données à proximité de la source (par exemple, capteurs) pour une faible latence).
Le choix de la bonne approche implique souvent des stratégies hybrides. Par exemple, des calculs en périphérie pour des alertes immédiates combinés à un traitement central par lots pour des analyses historiques approfondies, permettant aux entreprises d’adapter leurs opérations.
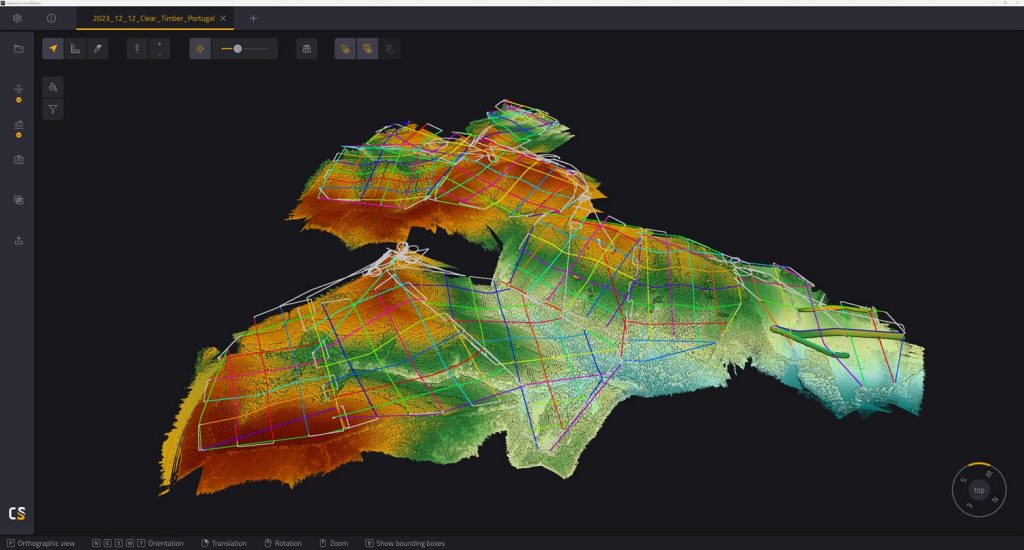
Données de nuages de points à haut volume provenant de plusieurs vols et traitées dans le logiciel YellowScan CloudStation
Avantages stratégiques d’un traitement efficace des données
La mise en œuvre d’une gestion efficace de l’information offre des avantages considérables aux entreprises:
- Une meilleure précision : Des résultats propres et bien traités permettent d’obtenir des résultats fiables.
- Des informations plus rapides : L’automatisation accélère l’obtention d’informations exploitables à partir des analyses.
- Évolutivité : Les bons systèmes gèrent des volumes de données croissants, ce qui est essentiel pour les données volumineuses.
- Rentabilité : L’automatisation des tâches réduit les efforts manuels et les dépenses opérationnelles.
- Conformité : Les opérations structurées facilitent le respect des lois sur la protection des données telles que le GDPR.
- Une meilleure collaboration : Les données normalisées facilitent le partage de l’information.
- Avantage concurrentiel : Des analyses plus rapides et de meilleure qualité permettent de prendre des décisions plus judicieuses.
- Amélioration des prévisions : L’analyse des données historiques permet de faire des prévisions plus précises.
Le traitement efficace des données permet d’en libérer la valeur, en les transformant en intelligence économique et en informations cruciales sur les clients.
Surmonter les défis courants en matière de traitement des données
Pour traiter efficacement les données, il faut anticiper les obstacles.
Assurer la qualité des données dans le traitement des données
Les difficultés sont souvent liées à la qualité des données. Les formats incohérents provenant de sources variées nécessitent une normalisation à l’aide d’outils de préparation. Les données manquantes ou erronées peuvent fausser l’analyse; les solutions passent par des contrôles d’erreurs et des stratégies claires pour combler les lacunes.
Gestion des ressources et de la sécurité
La gestion des ressources et la sécurité constituent des obstacles. Les gros volumes et les coûts des données volumineuses (comme les gros fichiers de balayage laser) exigent des ressources et un stockage puissants. Des stratégies de stockage efficaces, des procédures optimisées ou des services d’informatique en nuage (comme AWS, Microsoft Azure, Google Cloud) sont utiles. Une sécurité et une confidentialité robustes sont essentielles pour les données personnelles, nécessitant un cryptage, des contrôles d’accès et le respect des règles de conformité et de la loi sur la protection des données (par exemple, GDPR). Chaque responsable du traitement des données a des responsabilités en vertu de la loi.
Aborder la complexité des outils
Enfin, les outils peuvent constituer un obstacle. Certains logiciels de traitement présentent aux outils complexes une courbe d’apprentissage abrupte, nécessitant des compétences spécialisées ou un travail manuel important. L’atténuation des risques passe par la formation et la sélection de systèmes conviviaux. Il est conseillé de lire les termes techniques relatifs à des logiciels ou services spécifiques.
La planification proactive de ces défis facilite le déroulement des opérations.
Le traitement des données en action : Exemples concrets
L’impact de l « exploitation des données s » étend à de nombreux secteurs, montrant comment le traitement apporte de la valeur.
Applications géospatiales, environnementales et urbaines
La cartographie géospatiale et le LiDAR utilisent le traitement pour obtenir des cartes 3D précises, la classification de la végétation, le BIM ou l’inspection des infrastructures par balayage laser. L « environnement et l’agriculture l’utilisent pour surveiller l’utilisation des terres et guider l’agriculture de précision. L »urbanisme utilise l « analyse des données de capteurs pour améliorer la vie urbaine. La gestion des risques, par exemple, exploite l »analyse des données en temps réel pour prévoir les catastrophes.
Opérations commerciales et infrastructure
Les plateformes de commerce électronique analysent les données des clients pour formuler des recommandations et gérer les stocks grâce à des outils d « analyse puissants. Le secteur des transports et de la mobilité dépend du traitement des données de capteurs en temps réel (GPS, balayage 3D) pour la navigation autonome. Le secteur de l »énergie et des services publics utilise les données traitées pour la gestion des réseaux et la maintenance prédictive. De nombreuses entreprises utilisent ces informations.
Progrès en matière de soins de santé
Les soins de santé en tirent d’immenses bénéfices : le traitement des images médicales facilite le diagnostic, l « analyse des capteurs portés sur soi aide à surveiller la santé et l »analyse des dossiers des patients (en veillant à la protection des données) améliore les traitements. La science des données appliquée aux données traitées permet de découvrir des modèles.
En effet, une gestion efficace de l’information est essentielle pour transformer les données brutes en connaissances exploitables.

Classification de la végétation dans YellowScan CloudStation

Nuage de points d’un réseau routier périphérique utilisé pour la planification urbaine
Choisir les bons outils
Qu’il s’agisse de téraoctets de données de balayage laser ou de transactions avec les clients, un traitement efficace des données procure un avantage concurrentiel. Des défis subsistent. Il est essentiel de choisir les bons outils et le bon système logiciel. La bonne plateforme rationalise les flux de travail, garantit la qualité des données, gère le volume et fournit des analyses fiables. Le traitement intelligent est stratégique, car il réduit la dépendance à l’égard d’un tri manuel lent. Les bons outils logiciels comblent le fossé entre le potentiel brut et les résultats utiles.

Systèmes LiDAR YellowScan
Optimisez votre flux de travail LiDAR avec CloudStation
Pour les professionnels du LiDAR, la manipulation de données issues de nuages de points est essentielle. Des plateformes comme YellowScan CloudStation simplifient cette tâche. Cet outil logiciel sécurisé automatise les étapes de traitement complexes, garantit des résultats cohérents et aide les équipes à collaborer en partageant les données traitées et les informations. Ses capacités d’analyse spécialisées permettent de transformer plus rapidement les données LiDAR brutes en informations précieuses. Découvrez comment CloudStation simplifie votre flux de traitement LiDAR.
Questions fréquemment posées
Qu'est-ce que le traitement des données LiDAR ?
Transformer des nuages de points LiDAR 3D bruts en informations utiles telles que des cartes, des modèles ou des mesures à l’aide de méthodes et d’outils spécifiques.
De quoi a-t-on besoin pour traiter les données LiDAR ?
Des capteurs précis, de bonnes données GPS/IMU, des logiciels spécialisés et une puissance informatique suffisante (CPU, RAM, stockage).
Comment les données LiDAR sont-elles collectées ?
Utilisation de systèmes LiDAR sur des plates-formes envoyant des impulsions laser et mesurant le temps de retour. Ces systèmes comprennent souvent des composants électroniques avancés.
Qu'est-ce que LiDAR dans l'annotation des données ?
Étiquetage d’objets dans des nuages de points en 3D, souvent à l’aide de modèles de science des données et d’apprentissage automatique formés sur des données de balayage laser.
Pourquoi utiliser les données LiDAR ?
Il fournit des informations spatiales 3D précises et à haute résolution à partir de la numérisation 3D.
Comment recueillez-vous les données LiDAR ?
Avec une plate-forme équipée d’un système de balayage laser et d’une électronique de navigation pour capturer des données de nuages de points. Un stockage efficace sur le dispositif de collecte est également important.