Data Processing Explained: From Raw Data to LiDAR Insights

Making Sense of Data in a Data-Driven World
From Raw Data Overload…
We’re surrounded by raw data—from customer clicks online to 3D landscapes captured by laser scanning devices like LiDAR. Every day, vast volumes of information flow from sensors, online sales, customer surveys, or the LiDAR systems YellowScan offers.
But raw data doesn’t automatically equate to useful information—it needs to be processed with precision. While abundant data may seem beneficial, a large portion remains unused, disorganized, or underutilized, scattered across storage systems and offering little to no tangible value. To unlock its potential, data must be structured, refined, and made meaningful.
…To Actionable Business Insights
Real value emerges only when we effectively process this raw input through structured data operations. How do we transform numbers, text, and points into smarter business decisions? The key lies in data processing. Think of it as the essential bridge from messy input to clear, actionable information, enabling better analytics and informed choices. Whether improving business operations, exploring new tech frontiers, or using advanced tools like LiDAR which requires specific data processing steps, understanding efficient data handling is crucial for companies today. Let’s outline the core stages of data processing.

YellowScan Mapper+ LiDAR system scanning the landscape for environmental monitoring
What Is Data Processing?
Core Definition and Operations
At its core, data processing means performing systematic operations on raw data to convert it into meaningful, structured information. These tasks typically include sorting, cleaning (data preparation), format conversion, analysis, and secure data storage. Modern systems heavily rely on specialized software and automation (automatic data processing) for efficiency, ensuring higher data quality and consistency across large datasets.
Primary Goals and Approaches
The main goal? To transform disorganized input into organized, clear output ready for decision-making or further analytics. Good information handling makes data understandable and reliable for the business, supporting everything from daily operations to long-term strategy. In short, effective data management turns noise into meaning. This can range from manual work, prone to errors and slower time scales, to fully automated systems leveraging algorithms, data science, and machine learning. However, human checks remain important for trust, context, and ethical considerations, especially when dealing with personal data.
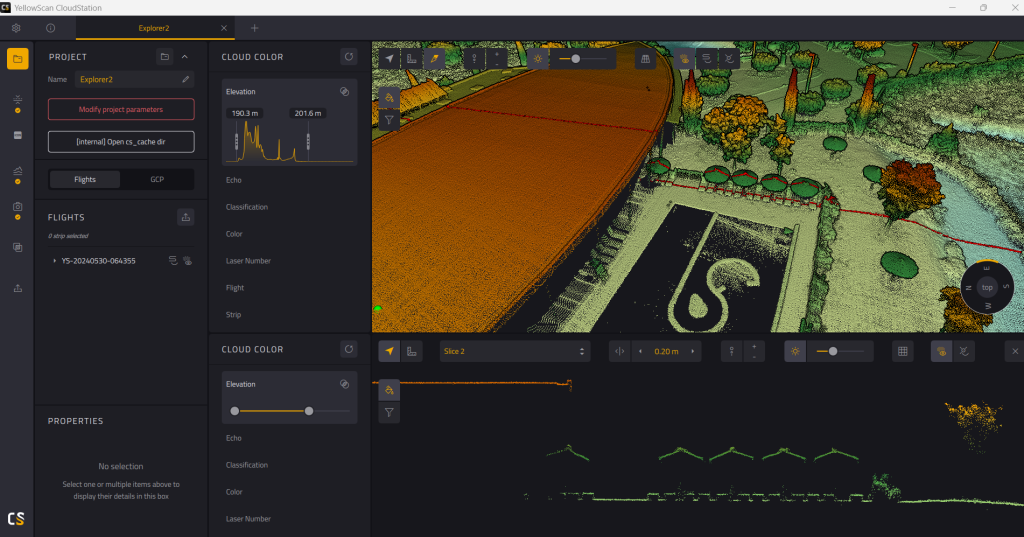
YellowScan CloudStation software ensures high data quality
The 6 Fundamental Steps of the Data Processing Cycle
Effective data operations typically follow this data processing cycle. Each step is crucial for overall success.
1. Data Collection
This initial stage involves systematically gathering raw data from relevant data sources – sensors, forms, customer interactions, business systems, electronic records, specialized collection devices, or equipment like LiDAR scanners. Input quality impacts all results; comprehensive and accurate collection is paramount for meaningful analytics.
2. Data Preparation (Cleaning)
Often the most time-consuming phase, data preparation involves tidying raw data: fixing errors, removing duplicates, handling missing values, and creating a consistent format for subsequent processing and analysis. Ensuring high data quality here prevents costly downstream errors. This step is vital (“garbage in, garbage out”) for trustworthy insights.
3. Data Input
Enter the clean data into the target data processing system (specific software, database like MySQL, or cloud storage services). Data needs to be in a format the system can read and understand, which might involve transformation or encoding.
4. Active Data Processing
Algorithms or AI process data based on rules or goals, performing calculations, sorting, classifying, or finding patterns to extract valuable insights. Powerful computing resources are often needed. Automation plays a huge role, using defined methods and specialized tools to handle complex tasks much faster than manual analysis.
5. Data Output
Present processed information usefully via reports, dashboards for analytics, structured files, or alerts. Output must be clear and easily interpretable by users or other systems for effective decision making. Visualizations often help communicate results.
6. Data Storage
Securely archive processed results and sometimes raw data for future use, compliance audits, or further analysis. Proper data storage strategies ensure availability and robust data protection. Optimized storage solutions (on-premise or cloud) are crucial for managing costs and security.
These six steps are foundational for handling simple datasets or complex big data analysis, including demanding 3D scanning projects.
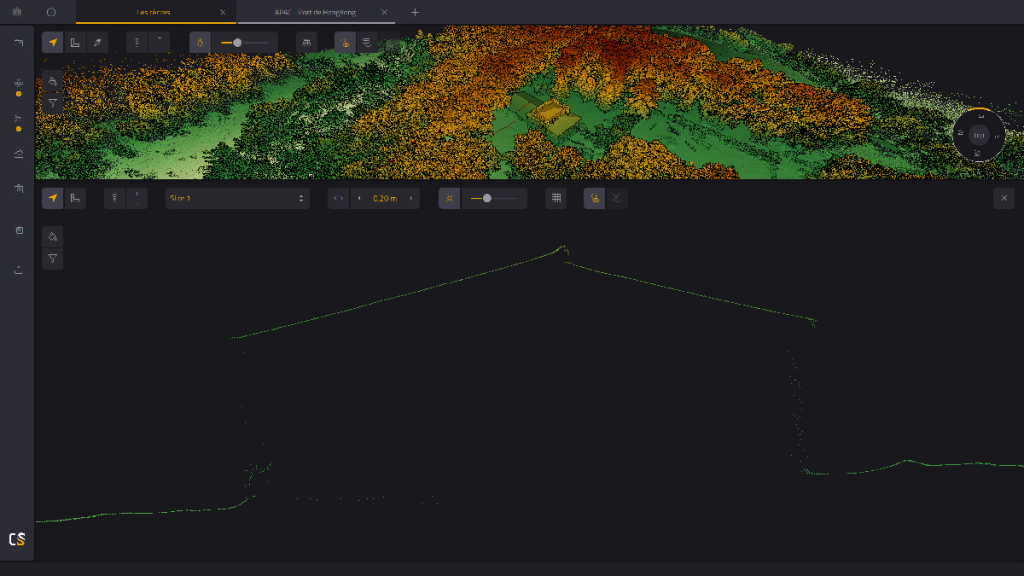
Clean point cloud slice viewed in YellowScan CloudStation
Exploring Different Types of Data Processing
Various data processing methods suit different needs, depending on factors like volume, speed, and connectivity. Understanding these types helps companies choose wisely.
Batch Processing
Collects data over time and processes it in large batches; suited for non-urgent, high-volume tasks like billing or large reports.
Real-Time Processing
Handles data almost instantly, essential for immediate reactions like fraud detection or autonomous navigation using real time data. Requires responsive systems.
Online Transaction Processing (OLTP)
Manages many fast, concurrent customer transactions (e.g., online orders), focusing on speed and accuracy within the operational system.
Distributed Processing
Splits big data workloads across multiple computers (often cloud-based) for speed and power in complex analysis, enabling large-scale data science.
Edge Processing
Performs initial data operations on or near the collection device (e.g., IoT sensors, drones), useful for low latency or poor connectivity by pre-processing information (processing data near the source (e.g., sensors) for low latency).
Choosing the right approach will often involve hybrid strategies. For example, edge computations for immediate alerts combined with central batch processing for deep historical analytics, allowing businesses to tailor their operations.
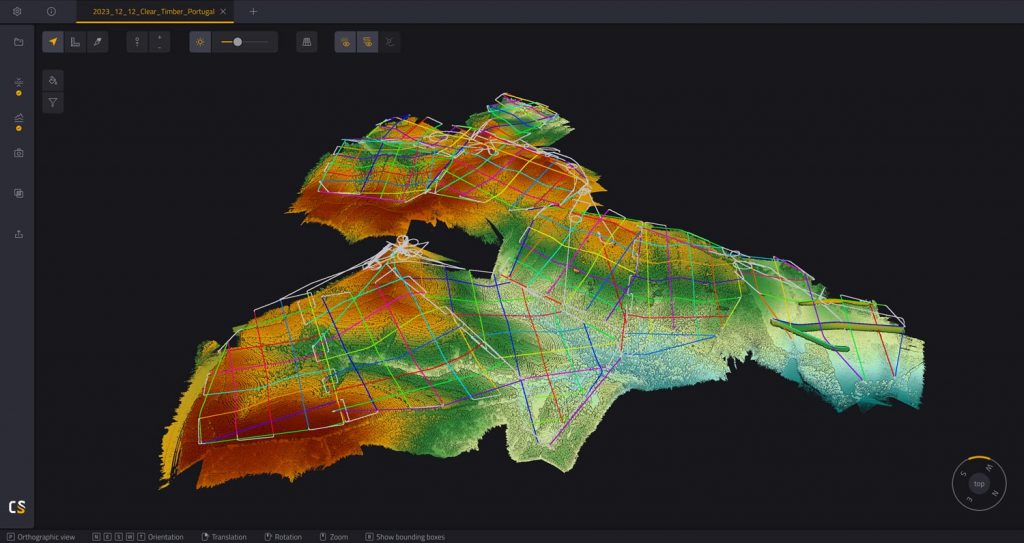
High-volume point cloud data from multiple flights processed in YellowScan CloudStation software
Strategic Advantages of Effective Data Processing
Implementing efficient information management yields significant business advantages:
- Better Accuracy: Clean, well-processed outputs lead to reliable results.
- Faster Insights: Automation speeds up deriving actionable insights from analytics.
- Scalability: Good systems handle growing data volumes, vital for big data.
- Cost Efficiency: Automating tasks reduces manual effort and operational expenses.
- Compliance: Structured operations aid adherence to data protection laws like GDPR.
- Better Collaboration: Standardized data facilitates information sharing.
- Competitive Advantage: Faster, better analytics inform smarter business moves.
- Improved Forecasting: Historical data analysis helps enable more accurate predictions.
Effective handling of data unlocks value, turning it into business intelligence and crucial customer insights.
Overcoming Common Data Processing Challenges
Effective data handling requires anticipating hurdles.
Ensuring Data Quality in Data processing
Challenges often relate to data quality. Inconsistent Formats from varied sources require standardization using preparation tools. Missing or bad data can corrupt analysis; solutions involve error checks and clear strategies for gaps.
Managing Resources and Security
Resource management and security pose obstacles. Large Volume and Costs from big data (like large laser scanning files) demand powerful resources and storage. Efficient storage strategies, optimized procedures, or cloud computing services (like AWS, Microsoft Azure, Google Cloud) help. Robust Security and Privacy is critical for personal data, requiring encryption, access controls, and adherence to compliance rules and data protection law (e.g., GDPR). Every data controller has responsibilities under the law.
Addressing Tool Complexity
Finally, the tools can be a hurdle. Some processing software presents Complex Tools with a steep learning curve, needing specialized skills or extensive manual work. Mitigation involves training and selecting user-friendly systems. It’s wise to read the technical terms for specific software or services.
Proactively planning for these challenges makes the workflow smoother.
Data Processing in Action: Concrete Examples
The impact of data operations spans many industries, showing how processing delivers value.
Geospatial, Environmental, and Urban Applications
Geospatial Mapping and LiDAR uses processing for accurate 3D maps, vegetation classification, BIM, or infrastructure inspection via laser scanning. Environment and Agriculture apply it to monitor land use and guide precision farming. Urban Planning uses sensor data analytics to improve city life. Risk Management, for example, leverages real-time data analysis to predict disasters.
Business Operations and Infrastructure
E-commerce platforms analyze customer data for recommendations and stock management via powerful analytics. Transportation and Mobility depend on processing real time sensor data (GPS, 3D scanning) for autonomous navigation. The Energy and Utilities sector uses processed data for grid management and predictive maintenance. Many companies use these insights.
Healthcare Advancements
Healthcare benefits immensely: processing medical images aids diagnosis, wearable sensor analytics help monitor health, and analysis of patient records (ensuring data protection) improves treatments. Data science applied to processed data helps uncover patterns.
Indeed, effective information management is key to turning raw data into actionable knowledge.

Vegetation classification in YellowScan CloudStation

Point cloud of a peripheral road network used for urban planning
Choosing the Right Tools
Whether dealing with terabytes of laser scanning data or customer transactions, efficient data processing provides a competitive edge. Challenges remain. Choosing the right tools and software system is crucial. The right platform streamlines workflows, ensures data quality, handles volume, and delivers reliable analytics. Smart processing is strategic, reducing reliance on slow manual sorting. Good software tools bridge the gap between raw potential and valuable results.

YellowScan LiDAR systems
Optimize Your LiDAR Workflow with CloudStation
For LiDAR professionals, handling data from point clouds is key. Platforms like YellowScan CloudStation simplify this. This secure software tool automates complex processing steps, ensures consistent results, and helps teams collaborate by sharing processed data and insights. Its specialized analysis capabilities help turn raw LiDAR data into valuable insights faster. Learn more about how CloudStation simplifies your LiDAR processing workflow.
Frequently Asked Questions
What is LiDAR data processing?
Turning raw 3D LiDAR point clouds into useful information like maps, models, or measurements using specific methods and tools.
What is needed for LiDAR data processing?
Accurate sensors, good GPS/IMU data, specialized software, and sufficient computer power (CPU, RAM, storage).
How is LiDAR data collected?
Using LiDAR systems on platforms sending laser pulses and measuring return time. These often include advanced electronic components.
What is LiDAR in data annotation?
Labeling objects in 3D point clouds, often using data science and machine learning models trained on laser scanning data.
Why use LiDAR data?
It provides accurate, high-resolution 3D spatial information from 3D scanning.
How do you gather LiDAR data?
With a platform carrying a laser scanning system and navigation electronics to capture point cloud data. Efficient storage on the collection device is also important.